The Database Class¶
A Class designed for the storing, retrieval and updating of results.
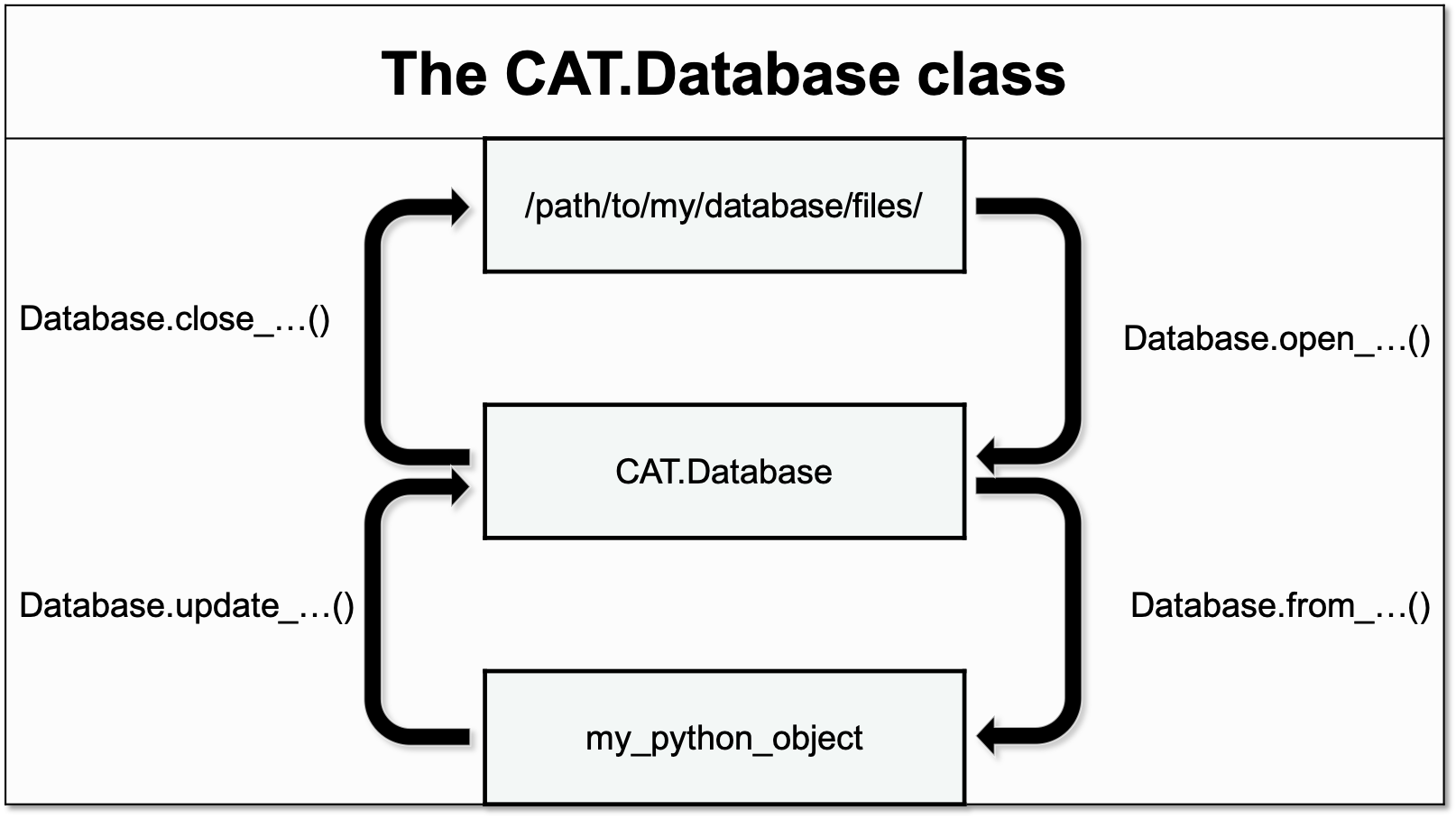
The methods of the Database class can be divided into three categories accoring to their functionality:
Opening & closing the database - these methods serve as context managers for loading and unloading parts of the database from the harddrive. These methods should be used in conjunction with
withstatements:import CAT database = CAT.Database() with database.open_csv_lig(db.csv_lig) as db: print('my ligand database') with database.open_yaml(db.yaml) as db: print('my job settings database') with h5py.File(db.hdf5) as db: print('my structure database')
open_csv_ligopen_csv_qdopen_yamlh5py.FileImporting to the database - these methods handle the importing of new data from python objects to the Database class:
update_csv()update_yaml()update_hdf5()update_mongodb()Exporting from the database - these methods handle the exporting of data from the Database class to other python objects or remote locations:
from_csv()from_hdf5()
Index¶
open_yaml |
|
open_csv_lig |
|
open_csv_qd |
|
DF |
|
update_mongodb |
|
update_csv |
|
update_yaml |
|
update_hdf5 |
|
from_csv |
|
from_hdf5 |
mol_to_file |
|
as_pdb_array |
|
from_pdb_array |
|
sanitize_yaml_settings |
Class API¶
-
class
CAT.data_handling.database.Database(path=None, host: str = 'localhost', port: int = 27017, **kwargs)[source]¶ The Database class.
Atributes: - csv_lig (str) – Path and filename of the .csv file containing all ligand related results.
- csv_qd (str) – Path and filename of the .csv file containing all quantum dot related results.
- yaml (str) – Path and filename of the .yaml file containing all job settings.
- hdf5 (str) – Path and filename of the .hdf5 file containing all structures (as partiallize de-serialized .pdb files).
- mongodb (None or dict) – Optional: A dictionary with keyword
arguments for pymongo.MongoClient. # noqa
-
class
open_yaml(path=None, write=True)[source]¶ Context manager for opening and closing the job settings database.
Parameters:
-
class
open_csv_lig(path=None, write=True)[source]¶ Context manager for opening and closing the ligand database.
Parameters:
-
class
open_csv_qd(path=None, write=True)[source]¶ Context manager for opening and closing the quantum dot database.
Parameters:
-
class
DF(df: pandas.core.frame.DataFrame)[source]¶ A mutable container for holding dataframes.
A subclass of
dictcontaining a single key ("df") and value (a Pandas DataFrame). Calling an item or attribute ofDFwill call said method on the underlaying DataFrame (self["df"]). An exception to this is the"df"key, which will get/set the DataFrame instead.
-
update_mongodb(database: str = 'ligand', overwrite: bool = False) → None[source]¶ Export ligand or qd results to the MongoDB database.
Parameters:
-
update_csv(df, database='ligand', columns=None, overwrite=False, job_recipe=None, opt=False)[source]¶ Update self.csv_lig or self.csv_qd with (potentially) new user provided settings.
Parameters: - df (pd.DataFrame (columns: str, index: str, values: plams.Molecule)) – A dataframe of new (potential) database entries.
- database (str) – The type of database; accepted values are ligand and QD.
- columns (None or list [tuple [str]]) – A list of column keys in df which (potentially) are to be added to self. If None: Add all columns.
- overwrite (bool) – Whether or not previous entries can be overwritten or not.
- job_recipe (None or plams.Settings (superclass: dict)) – A Settings object with settings specific to a job.
-
update_yaml(job_recipe)[source]¶ Update self.yaml with (potentially) new user provided settings.
Parameters: job_recipe (plams.Settings (superclass: dict)) – A settings object with one or more settings specific to a job. Returns: A dictionary with the column names as keys and the key for self.yaml as matching values. Return type: dict (keys: str, values: str)
-
update_hdf5(df, database='ligand', overwrite=False, opt=False)[source]¶ Export molecules (see the mol column in df) to the structure database. Returns a series with the self.hdf5 indices of all new entries.
Parameters: - df (pd.DataFrame (columns: str, index: str, values: plams.Molecule)) – A dataframe of new (potential) database entries.
- database (str) – The type of database; accepted values are ligand and QD.
- overwrite (bool) – Whether or not previous entries can be overwritten or not.
Returns: A series with the index of all new molecules in self.hdf5
Return type:
-
from_csv(df, database='ligand', get_mol=True, inplace=True)[source]¶ Pull results from self.csv_lig or self.csv_qd. Performs in inplace update of df if inplace = True, returing None.
Parameters: - df (pd.DataFrame (columns: str, index: str, values: plams.Molecule)) – A dataframe of new (potential) database entries.
- database (str) – The type of database; accepted values are ligand and QD.
- columns – A list of to be updated columns in df.
- get_mol (bool) – Attempt to pull preexisting molecules from the database. See inplace for more details.
- inplace (bool) – If True perform an inplace update of the mol column in df. Otherwise Return a new series of PLAMS molecules.
Returns: If inplace = False: return a new series of PLAMS molecules pulled from self, else return None
Return type: None or pd.Series (index: str, values: plams.Molecule)
-
from_hdf5(index, database='ligand', rdmol=True, close=True)[source]¶ Import structures from the hdf5 database as RDKit or PLAMS molecules.
Parameters: Returns: A list of PLAMS or RDKit molecules.
Return type:
-
hdf5_availability(timeout: float = 5.0, max_attempts: Optional[int] = None) → None[source]¶ Check if a .hdf5 file is opened by another process; return once it is not.
If two processes attempt to simultaneously open a single hdf5 file then h5py will raise an
OSError. The purpose of this function is ensure that a .hdf5 is actually closed, thus allowingto_hdf5()to safely access filename without the risk of raising anOSError.Parameters: Raises: OSError– Raised if max_attempts is exceded.
Function API¶
-
CAT.data_handling.database_functions.mol_to_file(mol_list, path=None, overwrite=False, mol_format=['xyz', 'pdb'])[source]¶ Export all molecules in mol_list to .pdb and/or .xyz files.
Parameters: - mol_list (list [plams.Molecule]) – A list of PLAMS molecules.
- path (None or str) – The path to the directory where the molecules will be stored. Defaults to the current working directory if None.
- overwrite (bool) – If previously generated structures can be overwritten or not.
- mol_format (list [str]) – A list of strings with the to-be exported file types. Accepted values are xyz and/or pdb.
-
CAT.data_handling.database_functions.as_pdb_array(mol_list, min_size=0)[source]¶ Converts a list of PLAMS molecule into an array of strings representing (partially) de-serialized .pdb files.
Parameters: - mol_list (list [plams.Molecule]) – A list of PLAMS molecules.
- min_size (int) – The minimumum length of the pdb_array. The array is padded with empty strings if required.
Returns: An array with m partially deserialized .pdb files with up to n lines each.
Return type: m*n np.ndarray [np.bytes |S80]
-
CAT.data_handling.database_functions.from_pdb_array(array, rdmol=True)[source]¶ Converts an array with a (partially) de-serialized .pdb file into an RDKit or PLAMS molecule.
Parameters: - array (n np.ndarray [np.bytes / S80]) – A (partially) de-serialized .pdb file with n lines.
- rdmol (bool) – If True, return an RDKit molecule instead of a PLAMS molecule.
Returns: A PLAMS or RDKit molecule build from array.
Return type:
-
CAT.data_handling.database_functions.sanitize_yaml_settings(settings, job_type)[source]¶ Remove a predetermined set of unwanted keys and values from a settings object.
Parameters: settings (plams.Settings (superclass: dict)) – A settings object with, potentially, undesired keys and values. Returns: A (nested) dictionary with unwanted keys and values removed. Return type: dict